Using Paxos to Build a Scalable, Consistent, and Highly Available Datastore
ABSTRACT
Spinnaker是一个实验性数据存储区,旨在在单个数据中心的大型商用服务器集群上运行。这篇文章介绍了Spinnaker基于Paxos的复制协议。Paxos的使用确保Spinnaker中的数据分区可用于读取和写入,只要其复制品的大部分存活。与最中一致的数据存储区相比,Spinnaker在读取时可以更快,但写入速度只有5%-10%。
INTRODUCTION
对数据库功能进行扩展时,一个有效的方法是在服务器集群使用手动分片,集群的每个节点负责部分数据并独立运行实例。后来也出现了新的数据库体系结构,可以进行自动化分片和负载平衡。
除了扩展要求外,还需要实现某种复制策略以实现高可用性和容错,一种可行方案是使用同步主从复制。但这不是一个理想的方法:
Limitations of Master-Slave Replication and the Case for Paxos
在传统的双向同步复制中,很可能存在这样的问题:
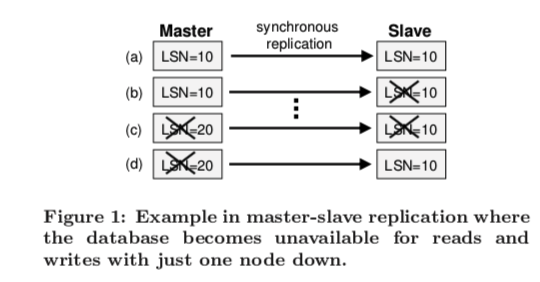
随着时间序列a-b-c-d的进行,从节点在b崩溃,在d恢复,主节点在c接受完写入后崩溃。此时从节点无法获取最新状态。因为根据要求,所有的写入都必须要路由到master,再由master的日志发送到slave。
因此,三向复制通常与商品服务器一起使用,可以避免其中一个节点数据丢失带来的问题或者便于在线升级。当有3个或多个副本时,Paxos协议被广泛认为是唯一经过验证的解决方案。Paxos解决了在2F + 1副本状态达成共识的一般问题,同时可以解决F故障。但paxos过于复杂和缓慢。
Strong vs. Eventual Consistency
在分布式系统中,一致性模型描述了不同副本如何保持同步。强一致性保证所有副本看起来与应用程序完全相同,这是构建应用程序的理想属性。CAP定理中提出,一致性,可用性和分区容差,最多只能保证两个。
Spinnaker
本文介绍了Spinnaker环境中一致性复制问题的解决方案,这是一个实验性数据存储,旨在在单个数据中心的大型商用服务器集群上运行。Spinnaker具有基于密钥的范围分区,3向复制和事务性get-put API。
对于复制,Spinnaker使用基于Paxos的协议,该协议将日志提交和恢复处理集成在一起。Spinnaker是CA系统的一个示例。
RELATED WORK
Two-Phase Commit
2PC是维持副本一致性的方法之一,具体可以参考。
由于其性能较差,所以一般不会使用。
Database Replication
与spinnaker相比,数据库备份主要关注在单个未分区数据库的上下文。
Dynamo, Bigtable, and PNUTS
亚马逊的Dynamo是一个基于key-value的存储,它使用最终的一致性来提供高可用性和分区容错。
谷歌的Bigtable是一个可扩展的数据存储区,可为单一操作事务提供强大的一致性支持。
而Yahoo的PNUTS也是一个可扩展的数据存储区,支持时间线一致性和单一操作事务。
DATA MODEL AND API
Spinnaker的数据模型和api与Bitable类似。数据以表格和行列的形式组成,每一行有一个唯一ID,并且包含了多个列(每一列又有其版本号和值)。至于API则是:
- get(key, colname, consistent): consistent是一个flag,true时选择强一致性,返回最新的值
- put(key, colname, colvalue)
- delete(key, colname)
- conditionalPut(key, colname, value, v):v代表版本号,插入时该列的版本需等于'v'
- conditionalDelete(key, colname, v)
版本号是单调递增的整数,由Spinnaker管理并通过其get API暴露出去,因此我们可以这样使用api来更新某个计数器:
1 | c = get(key, “c”, consistent=true); |
每个API调用都作为单个操作事务执行。
ARCHITECTURE
本文主要介绍Spinnaker的架构。
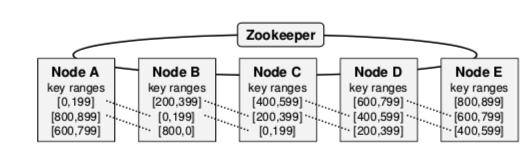
Spinnaker通过范围分区的方式将一个表的行分布到集群中。以下图为例,这个Spinnaker集群有5个节点,每个节点都有一个key范围,这个范围会被备份到后面的N-1个节点中(这里N为3)。这样节点A-B-C形成key范围[0,199]的群组,节点B-C-D形成key范围为[200,399]的群组。
Node Architecture
Spinnaker每个节点都包含多个组件,每个组件都是线程安全的,这样就可以多线程地支持节点上三个key范围的其中一个使用。
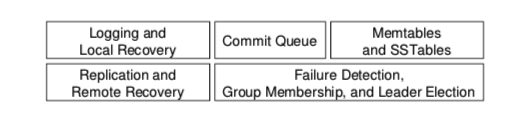
每个节点的群组都有自己独立的逻辑LSN,以便共享相同的日志。
- commit queue是用来追踪pending的写入,在接收到群组足够的答应之后此才会将写入提交
- memtable则是用来放置提交的写入,定期排序并刷新到称为SSTable的不可变磁盘结构中
- SSTables按密钥和列名称编制索引,以便高效访问,并在后台中合并小的SSTables
Zookeeper
Zookeeper用于在Spinnaker中提供差错容忍和分布式协调服务。通过提供存储元数据和管理节点故障等事件的集中位置,Zookeeper极大地简化了Spinnaker的设计。
通常,Spinnaker节点和Zookeeper之间交换的唯一消息是心跳。
THE REPLICATION PROTOCOL
本节介绍Spinnaker的复制协议。该协议基于每个队列应用。
首先是每个群组都会有一个leader,而其它两个节点就是follower。这个协议有两个阶段:一是leader选举,后面则是称为quorum的阶段,leader会提出写入,follower会接受这个提议。
下图就是稳定状态下的复制协议流程:
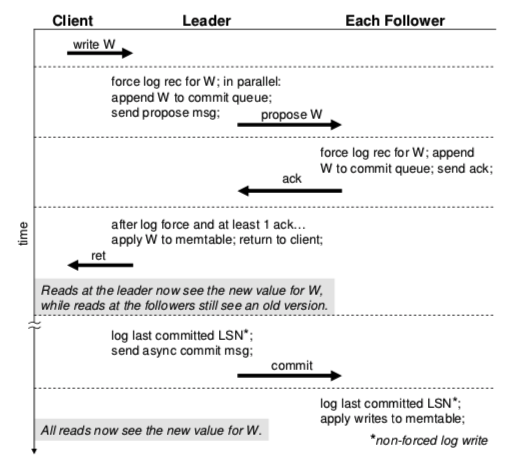
首先是客户端提交写入W,被路由到相关key范围的leader节点。leader并行地启动日志刷到磁盘、将W添加到commit queue并发送一个消息到followers。
follower在接收到消息后,将W日志记录到磁盘,附加W到commit queue,并对leader作出应答。
leader收到至少一个应答后就会将W写入memtable。
另外,leader会周期性地发送异步消息给followers,以让followers将到某个LSN范围内的pending写入应用到memtable。对于强一致性来说。所有的读取都路由到leader;而时间轴一致性则可以路由到任意节点。因此由上图可得,一共会有三次log force和四次消息传递。
Conditional Put
Conditional Put与常规put的唯一区别就是前者需要检查版本是否匹配,如果不符合,不会写入任何数据,并且会向客户端返回错误代码。Conditional Put在组群的每个节点上具有相同的结果。
RECOVERY
接下来会讨论一个群组在某个节点挂掉后如何恢复。一个属于三群组的节点是共享日志、并行恢复的,因此这里主要以一个群组为例。
Follower Recovery
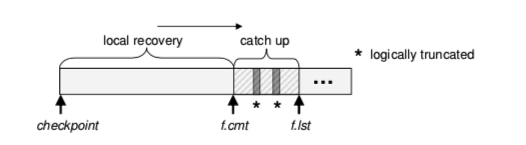
follower的恢复有两个阶段:local recovery和catch up。
首先假设f.cmt和f.lst分别是follower最近提交的日志LSN和最后的LSN,在local recovery阶段,follower会重播f.cmt之前的日志记录,至于f.cmt之后的,在catch up阶段,follower会先通知leader它的f.cmt,leader会将f.cmt之后提交的写入作为应答,然后follower会阻塞其他的写入,重播这些日志。
由于实际中,一个节点最旧的那部分日志很可能已经被SSTable捕获,如果catch up阶段需要,leader无法访问这部分日志。因此SSTable会记录其包含写入的日志LSN范围,在catch up无法满足要求时,SSTable会帮助获取这部分日志。
Logical Truncation of the Follower’s Log
前面提到过,f.cmt之后的写入状态是无法确定的,因为leader可能尚未提交,也可能旧leader提交了,但其挂掉后,新leader丢弃了部分日志。
为了解决这个问题,我们采用的是logical truncation的方法,则将f.cmt与f.lst之间日志的LSN记录到LSN的跳表中,如下:
Leader Takeover
当leader挂掉时,一个集群的key范围将变得不可写入,新leader会被选出,并保证老的leader的所有commit日志都会被包括进来。
如果老的leader挂掉了,有些可能在follower的处于pending状态下的,但已经在老leader里commit的日志。新leader的解决方法如下:

LEADER ELECTION
本文主要描述Spinnaker的leader选举协议,该协议是基于每个群组运行。当一个群组的leader挂掉或者系统重启后本地恢复时,leader的选举就会被触发。
Zookeeper’s Data Model and API
Zookeeper的数据模型与文件系统的目录树类似,树中的节点都由从根开始的路径标示,例如/a/b/c。这些znode包含了相关的二进制数据。
znode既可以是持久化的也可以是临时的,另外znode还可以包含一个顺序属性,使Zookeeper在创建时为znode添加一个唯一的,单调递增的标识符。
The Leader Election Protocol
每个Spinnaker节点都包含一个Zookeeper客户端。
假设r是进行选举的群组的key范围,那么选举所需要的信息都存储在Zookeeper的/r下。leader选举之前会有一个节点清除上一轮leader选举的状态。紧接着,群组的节点会宣称自己是candidate,此时会添加一个临时的znode在目录/r/candidates下。一旦有大多数的节点成为了candidate,就选择最大lst的节点作为leader。具体过程如下:

DISCUSSION
Availability and Durability Guarantees
使用N=3的默认备份设置时,Spinnaker会在日志成为大多数时才会真正commit。只要大多数节点启动,群组就可以继续进行强一致的读写操作。
在正常情况下,即使其中3个节点中的2个永久失败,群组也不会丢失已发送的数据。 但是,如果一个群组的领导者及其一个follower在快速连续中永久失败,那么一个小写的commit窗口可能会丢失。
Multi-Operation Transactions
目前,Spinnaker中的每个API调用都作为单个操作事务执行,但可以通过对其复制协议和恢复过程进行相当适度的扩展来支持多操作事务。
基本思想是让事务创建多个日志记录,但仅在提交时为一批日志记录调用复制协议。 然后在恢复期间,首先使用Paxos将日志的副本置于一致状态,然后是本地(每个节点)redo和撤消恢复过程。