特征选择与稀疏学习
子集搜索与评价
对一个学习任务来说,有些属性很关键,而从给定的特征集合中选择出相关特征子集的过程,就叫"特征选择"(feature selection)。
除了无用特征,还有一类冗余特征,它的信息是从其它特征推断出来的。大部分时候这些特征是不起作用,但有时也会起到中间特征的作用,使得学习更加方便。
提取特征的一个可行做法是先产生一个候选子集,评估好坏,再根据评估结果去产生下一个候选子集,依次迭代。
- 子集搜索
这第一个环节就是"子集搜索",给定特征集合\({a_1, a_2, …, a_d}\)。对于前向搜索,对这个d个特征子集进行评价,假设\(\{a_2\}\)最优,接着从剩下的d-1个特征选一个特征,假设此时两特征集合\(\{a_2, a_4\}\)最优,并且由于\(\{a_2\}\)效果更好,则选择\(\{a_2, a_4\}\)。依次进行,直到最优的候选子集不如上一轮选定集合,则停止生成候选子集。而对于后向搜索,则是每次减去一个无关特征。
这种贪心的策略可能会遇到这样一种情况,第三轮选了\(\{a_2,a_4,a_5\}\),而第四轮却可能是\(\{a_2,a_4,a_6,a_8\}\)更好。这是不可避免的。
- 子集评价
给定数据集D,假设D中第i类样本所占的比例为\(p_i(i=1,2,..,|y|)\),另外对于属性子集A,假定根据其取值将D划分为V个子集:\(\{D^1, D^2, ,,., D^V\}\),每个子集中的样本在属性A上取值相同,则计算属性子集A的信息增益: \[ Gain(A) = Ent(D) - \sum_{v=1}^V \frac{|D^v|}{|D|}Ent(D^v) \\ Ent(D) = - \sum_{k=1}^{|y|} p_k log_2p_k \] Gain(A)越大,意味着特征子集A对数据集D的划分与样本标记信息对于D的真实划分,差异越小,则越有助于分类。
常见的特征选择方法有:过滤式、包裹式、嵌入式
过滤式选择
过滤式方法先对数据集进行特征选择——"过滤",然后再训练学习器。Relief是一种过滤式特征选择方法,其设计了一个"相关统计量"来度量特征的重要性,该统计量是一个向量,每个分量对应一个初始特征,特征子集的重要性由子集中每个特征所对应的相关统计量分量之和所决定。
Relief的关键是如何确定相关统计量。假设样本为\(\{(x_1,y_1), (x_2, y_2),…, (x_m,y_m)\}\)。对于每个样本\(x_i\),该算法先在\(x_i\)的同类样本中寻找最近邻\(x_{i,nh}\),再从异样样本中寻找其最近邻\(x_{i,nm}\)。相关统计量对应属性j的分量为: \[ \delta^j = \sum_i -diff(x_i^j, x_{i,nh}^j)^2 + \sum_{l\neq k}(x_i^j, x_{i,nm}^j)^2 \] 如果属性j为离散型,则\(diff(x_a^j, x_b^j)^2\)的值域为[0, 1]。若是连续型,则是\(|x_a^j-x_b^j|\)。
由上式可以看出,若\(x_i\)与同类样本更近,则属性j对于区分同类与异类的样本是有益的。
上述Relief算法是为二分类问题准备的,其扩展变形Relief-F则能够处理多分类问题: \[ \delta^j = \sum_i -diff(x_i^j, x_{i,nh}^j)^2 + \sum_{l\neq k}(p_l \times (x_i^j, x_{i,nm}^j)^2) \] 其中\(p_l\)为第l类样本在数据集D中所占的比例。
包裹式选择
包裹式特征选择直接把最终将要使用的学习器性能最为特征子集的最终评价标准,因为是为了目的学习器选择特征子集,因此往往比过滤式选择性能更好。
LVW是其中的代表,算法描述为:
1 | 输入: 数据集D |
由于特征搜索时使用了随机策略,因此每次特征子集评价都需要训练学习器,因此开销很大,我们设置停止条件控制参数。
嵌入式选择与L1正则化
嵌入式特征选择是将特征选择与学习器训练过程融合为一体,给定数据集\(D = \{(x_1,y_1),(x_2, y_2),…,(x_m,y_m)\}\),考虑简单的线性回归模型,以平方差为损失函数: \[ min_w \sum_{i=1}^m(y_i-w^Tx_i)^2 \] 为了避免过拟合,加入范数正则化: \[ min_w \sum_{i=1}^m(y_i-w^Tx_i)^2 + \lambda||w||^2_2----L_2范数 \\ min_w \sum_{i=1}^m(y_i-w^Tx_i)^2 + \lambda||w||_1----L_1范数 \] L1范数相对于L2范数更容易带来稀疏解,即它求得的w具有更少的非零分量。假设x只有两个属性,同理解w也只有两个分量,因此我们画出等值线:
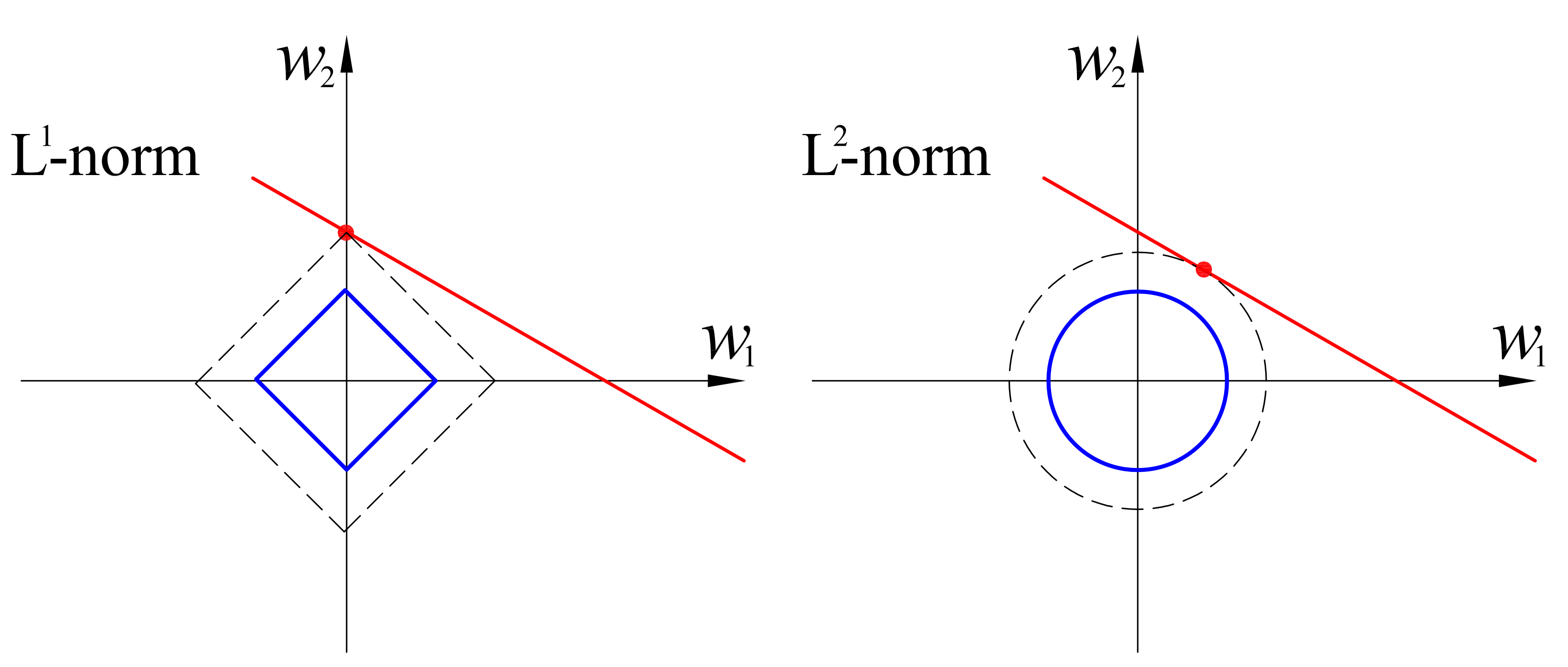
可以看到的是,由于上面w的解必须要在误差项与正则化项之间折中,因此即有图中的误差项等值线与正则化项等值线相交,采用L1范数时,相交点一般在坐标轴上,则w1或者w2为0。这意味着采用L1范数正则化的结果是得到了对应w的非零分量的特征。
其特征选择过程与学习器训练融为一体,同时完成。
稀疏表示与字典学习
假设数据集D是一个矩阵,行对应每个样本,列则对应特征,特征选择考虑的是如何使得矩阵变得稀疏,即某些特征与学习任务无关,我们可以去掉这些咧从而提高学习速度。
但考虑另一种稀疏性,即D对应的矩阵中存在很多零元素。但样本具有这样的稀疏表达形式时,学习任务会得到许多好处,例如线性支持向量机能使大多数问题变得线性可分,同时也不会带来存储上的负担。
若提供的数据集是稠密的,我们需要学习出一个"字典",从而使得稠密数据转化为"恰当稀疏"的数据。
给定数据集\({x_1,x_2,…,x_m}\),字典学习的最简单形式为: \[ min_{B,\alpha_i} || x_i-B\alpha_i ||^2_2 + \lambda \sum_{i=1}^m || \alpha_i ||_1 \] 其中B为字典矩阵,\(\alpha_i\)则是样本\(x_i\)的稀疏表示。该式的第一项是希望\(\alpha_i\)能够尽可能重构样本,而第二项则是希望\(\alpha_i\)尽可能稀疏。
压缩感知
在现实任务中,我们常希望能够通过部分信息来恢复全部信息,假定有长度为m的离散信号x,采样后得到长度为n的信号y,其中n<<m: \[ y = \phi x \] 其中\(\phi \in R^{n \times m}\)表示对信号x的测量矩阵,而由于n<<m,因此上式是一个欠定方程。
现在假设存在某个线性变换\(\psi \in R^{n \times m}\),使得y表示为: \[ y = \phi \psi s = As \] 若能恢复出s,我们也可以最后恢复出x。虽然这个问题仍然是欠定的,但如果s具有稀疏性,我们就可以解决这个问题了。这里A的作用则类似于字典,能够将信号转换为稀疏表示。
压缩感知分为"感知测量"和"重构恢复"两个阶段,前者关注如何对原始信号进行处理以获得稀疏样本表示,后者则是基于稀疏性从少量观察中恢复原信号。
对于大小为nXm的矩阵A,若存在常数\(\delta_k \in (0, 1)\)使得对任意常量s和A的所有子矩阵\(A_k \in R^{n\times k}\)有: \[ (1-\delta_k)||s||_2^2 \leq || A_ks ||_2^2 \leq (1+\delta_k)||s||_2^2 \] 则称A满足k限定等距性,此时可通过下面的优化问题从y中恢复出稀疏信号s: \[ min_s || s ||_0 \\ s.t. \ \ y = As \] 但该式涉及到L0范数最小化,这是一个NP难的问题,但由于L1范数最小化在一定条件下与L0范数最小化问题同解,因此有: \[ min_s || s ||_1 \\ s.t. \ \ y = As \]