The Design of a Practical System for Practical System for Fault-Tolerant Virtual Machines
ABSTRACT
一个容错虚拟机分布式系统的设计
INTRODUCTION
对于分布式系统而言,有很多通用的容错方法:
- 主备服务器:在主服务器挂掉了,由备份服务器接管工作。需要大量带宽在主备间传输状态;
- 状态机方法:让两台机器初始化为相同状态,然后接受相同的输入,使得两台机器保持同步。保持两台机器同步的额外信息数量远少于改变主服务器的状态量;然而可能存在一些不确定的操作(如读取时钟),因此必须同步这些不确定操作的结果;
primary和backup之间传递deterministic operation + non-deterministic operation's result;
BASIC FT DESIGN
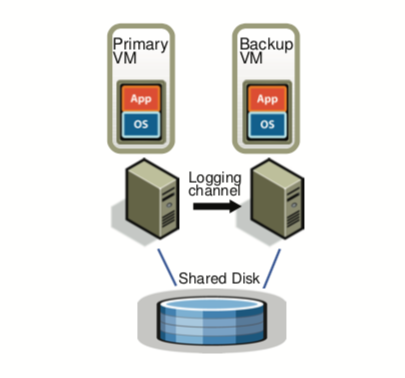
上图展示了容错虚拟机的基本配置。primary VM和backup VM运行在不同的物理机上,并保持同步(backup会稍有迟延),并且它们使用共享磁盘空间。primary VM将接收到的输入通过Logging channel传送到backup VM。虽然两者都执行相同的输入,但只有primary VM会输出返回给client,因为backup VM会被hypervisor终止掉。backup会通过ack应答来保证没有数据丢失。primary VM和backup VM之间会通过 heartbeat 进行 fail 检测。
Deterministic Replay Implementation
正如上文提到过的,让两台机器处于相同的初始状态,然后以相同的顺序提供相同的输入,这样两台机器就能经历相同的状态序列并产生相同的输出。
但由于存在非确定性的事件(虚拟中断)或者操作(读取处理器时钟技术器),这样会影响VM的状态。
这里的挑战在于:
- 需要捕捉全部的输入和非确定性操作,以此保证backup是确定性;
- 需要将所有的输入和非确定性操作应用到backup中;
- 需要保证系统高效;
设计方案:将所有的输入和非确定性操作记录到日志文件,并且对于非确定性操作,还必须要把相关的状态信息记录到日志文件中。
FT Protocol
FT协议是用于logging channel的协议
- 输出要求:
如果primary宕机了,backup会接管它的工作,并且backup会执行与primary一致的输出
- 输出规则:
在backup VM收到并应答所有的日志之前,primary都不会把输出发送给外部
并且,基于这个输出规则来说,primary VM不会停止执行,它只是延迟发送输出。
FT协议的流程如下图:
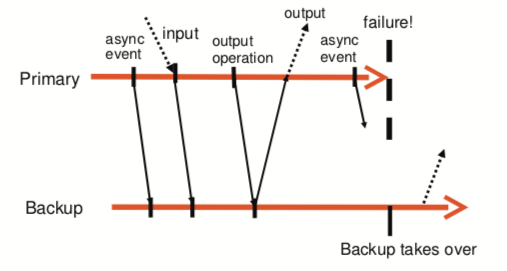
但这里存在一个小问题,如果 primary 宕机了,backup 不能判断它是在发送了 output 之前还是之后宕机的,因此 backup 会再发送一次 output,但可以通过以下方式解决:
- 诸如TCP等网络协议能够检查丢失或者重复的数据包;
Detecting and Responding to Failure
如果是backup宕机,primary会停止发送日志。如果primary宕机,情况复杂一点,backup会接替它的工作,在执行完接收到的日志记录之后,成为primary真正对外输出。
存在一些方法检测宕机,比如通过UDP heartbeat来检测primary与backup之间是否正常通信。另外,还会监控logging channel的日志流量。
但这些方法仍然无法解决split-brain问题,即primary和backup同时宕机。为了解决这个问题,该设计使用了共享存储,提供了一个原子操作test-and-set,primary和backup无法同时在该区域操作。
PRACTICAL IMPLEMENTATION OF FT
Starting and Restarting FT VMs
在设计系统时,需要考虑如何启动/重启一个与primary状态一致的backup?
VMware VMotion能够使得一个运行中的VM从一个server迁移到另一个server,并且只需要很短的中断。这里做了一些改动,并不是进行迁移,而是在远程主机上克隆一个,并使得源VM进去logging mode,目标VM进入replay mode。
除此之外,由于VM都运行在同一个集群,访问同一个存储区域,因此在选择哪个server作为backup时,是由primary同志集群服务实现的。
Managing the Logging Channel
存在几种实现方法,管理logging channel的流量。
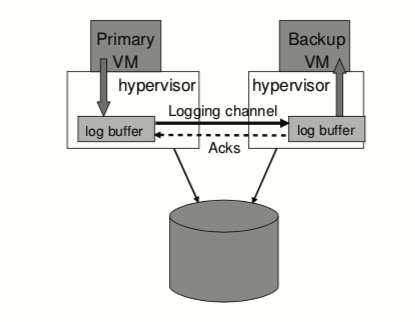
如下图所示,hypervisor维持了一个很大的log buffer,存着primary和backup的日志。primary往buffer写入日志,而backup则从中读取日志。这两者的操作类似于一个队列,backup遇到的空buffer,影响不大。但如果primary遇到满的buffer,会停止写入并停止对外输出。
因此我们需要一种机制来降低primary的速度,在logging channel增加额外的信息来通知primary,降低server上CPU的使用限制。
Operation on FT VMs
另一个需要关注的实际问题是如何应对primary的多种控制操作。一般来说,大多VM操作只会在primary初始化,然后将必要的信息发送给backup。唯一一个在primary和backup独立的操作是VMotion,请注意,VMware FT确保两个VM都不会移动到另一个VM所在的服务器,因为这种情况不再提供容错功能。
对于primary来说,VMotion会导致backup与primary断开连接,然后重连。
对于backup来说,由于backup同时还在重放primary的操作和完成IO(VMotion需要停顿IO),所以VMotion会比较复杂。VMware的方法是当backup VM位于VMotion的最终切换点时,它通过日志记录通道请求primary VM暂时停顿其所有IO。 然后,backup VM的IO将在单个执行点自然停顿,因为它重放primary VM执行静止操作。
Implementation Issues for Disk IOs
- 磁盘操作是非阻塞的、可以并行操作,这样会导致non-determinism;
解决方法:检测IO races,并强制这些操作串行
- 磁盘操作很可能与其它应用或者OS在访问同一块内存时产生竞争,因为磁盘操作是通过DMA实现的,会导致non-determinism;
解决方法;设置页保护,但修改MMU的页保护代价太高了。因此这里是用了bounce buffer的设计,这是一块与访问内存等大的buffer。读操作将内存读入buffer,待IO完成了再写回内存;写操作则是将内容写入buffer,稍后写入磁盘。
- 当backup接管失效的primary,成为新的primary后,无法确定磁盘IO是否已经完成;
解决方法:发送一个error,表明所有IO都失败了,然后重新执行磁盘IO操作,无论是否已经成功
Implementation Issues for Network IO
系统设计了关于网络的性能优化。
由于这些优化很多都基于异步的执行,而这些操作可能回导致non-determinism,因此一个重要的问题是如何禁止这些异步的网络优化。
我们采取两个办法来提高VM的网络性能:
- 实现集群优化,减少VM的traps和中断;
- 降低发送packets的延迟,减少发送日志消息和等待ack的时间,方法是避免线程切换;
DESIGN ALTERNATIVES
Shared vs Non-shared Disk
存在一个可替代的设计方法,那就是primary和backup拥有独立的虚拟磁盘(non-shared),保证磁盘内容的同步,这样disk就变成了VM内部的状态。如下图:
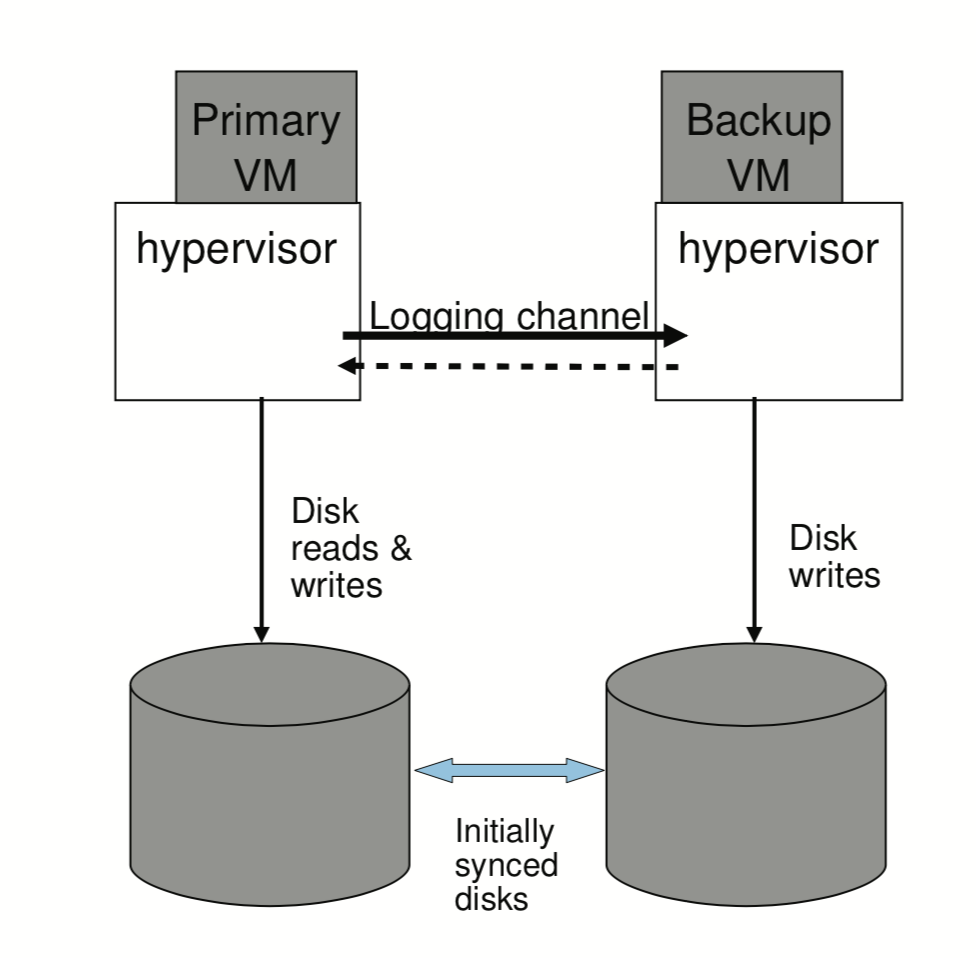
这种设计的一大缺点就是为了保证容错,必须要确保虚拟磁盘以某些方法同步。在面对split-brain问题时,需要使用一个第三方服务器(primary和backup都能访问的)
Executing Disk Reads on the Backup VM
在我们的设计中,磁盘的读入不是直接输入backup的,而是通过logging channel获取相关读取信息的。
这种设计方案可以减少logging channel的流量,但面临更多的小问题:
- 因为backup要执行读取,这样会降低backup VM的执行速度;
- 要处理好失败的磁盘读取操作,如果backup失败,primary成功,需要重试;如果反过来,primary需要通过logging channel告知backup不需要做备份;
- 在shared disk的情况下,如果primary在读完磁盘之后想马上执行写入到相同位置,则必须要等待backup也读取完毕;