MapReduce
Introduction
MapReduce是谷歌提出的一种编程模型,主要目的是为了处理和生成大数据。通过定义map函数来处理key/value对,生成中间键值对,而reduce函数则是用来归并这些中间键值对。
以这种编程模式来实现的程序会自动在大的集群上并行执行。
Programming Model
运算时键值对输入,产生另外的一系列键值对。Map函数是用户编写,输入键值对,产生键值对,将具有相同的中间key的值传到reduce函数。
reduce函数则是接收上面的中间键值对,将那些value合并起来。
Example
考虑计算文档单词数目的伪代码:
1 | map(String key, String value): |
Types
map和reduce函数都是有类型的:
1 | map (k1, v1) --> list(k2, v2) |
More Examples
一些应用了mapReduce的例子:
- Distributed Grep
- Count of URL Access Frequency
- Reverse Web-Link Graph
- Term-Vector per Host
- Inverted Index
- Distributed Sort
Implementation
论文介绍了谷歌内部的使用。
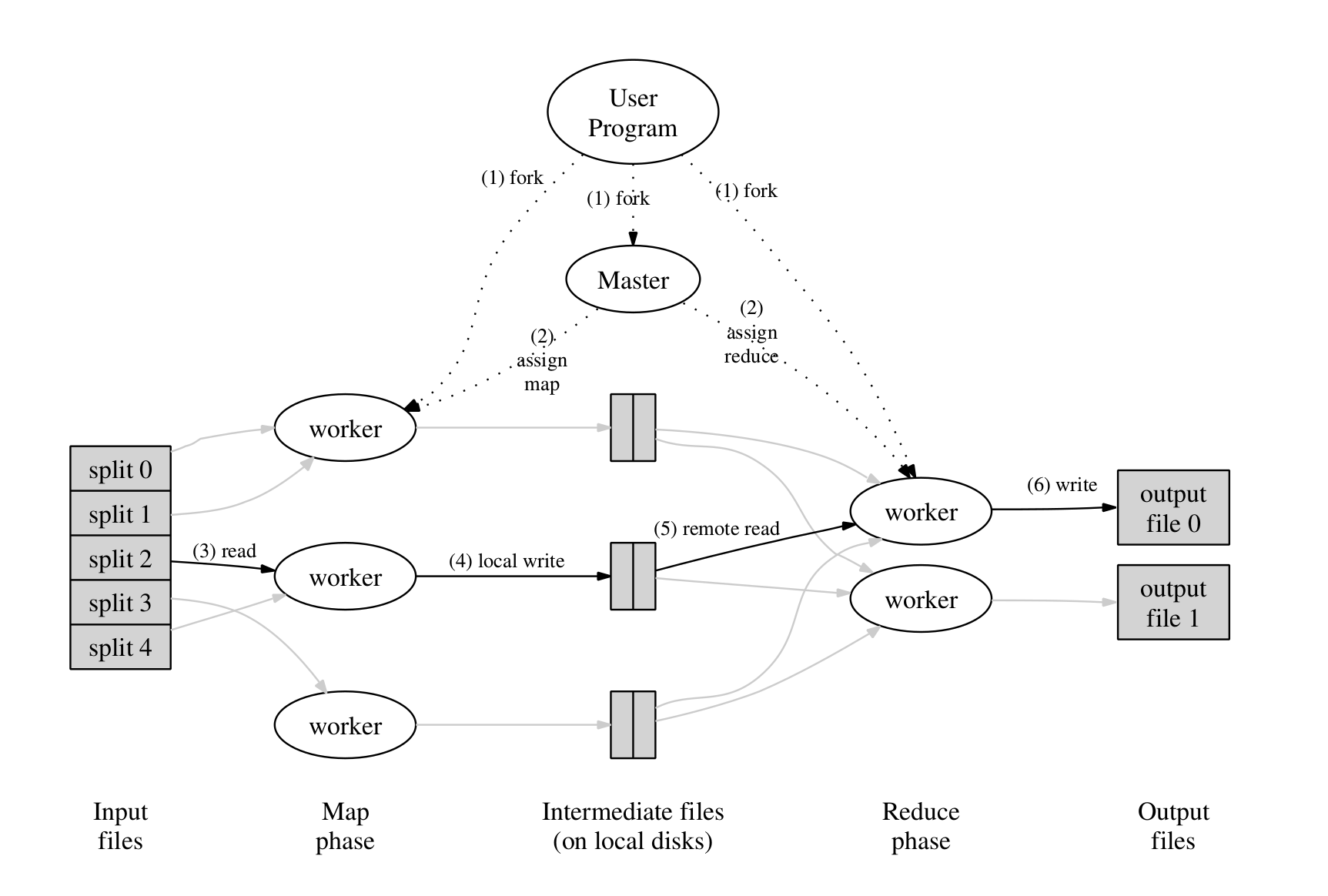
Execution Overview
- MapReduce库先将input分成M份(16MB-64MB),然后启动集群上多个机器上的进程;
- 其中一个进程是master,其它都是worker;
- 分配了map任务的worker会读取那M份输入的一份,解析键值对,将其传到自定义的Map函数中,产生的中间键值对将会缓存起来;
- 缓存的内容会被周期性写入到磁盘上,这里磁盘被分成R个区域。写入后的位置信息将会反馈到maser,master再将位置信息传给reduce的worker;
- reduce的worker将会调用RPC去读取缓存,并根据中间结果的key进行排序,使得相同key的键值对分到一个组;
- reduce worker将会遍历键值对,然后将key和相关联的values传到自定义的reduce函数里;
- 当所有任务完成后,master将会从MapReduce中返回;
Master Data Structures
master保存着多种数据结构,比如worker的状态。
另外master还是map任务和reduce任务关于文件位置的沟通渠道。
Fault Tolerance
Worker Failure
master周期性地pingworker,如果没有响应,就认为worker失败了。在失败worker上完成的map任务会设置为idle状态,而还在失败worker上运行的map或者reduce任务都会被设置为idle状态。
完成的map任务此时还需要重新执行,因为中间结果被存在失败机器的磁盘上;而reduce任务不需要重新运行,因为它的输出存储在全局文件系统。另外,所有的reduce任务都应该知晓任务在重新执行,以便读取到正确磁盘上的中间结果。
Master Failure
一般情况下,是将master的数据结构持久化。一旦master任务挂了,就从上次的checkpoint点重新起来。
Semantics in the Presence of Failures
当用户的map和reduce函数是确定性的,那么MapReduce产生的结果也是唯一确定的,这是依赖于Map和Reduce任务的原子性提交实现的。
而对于非确定性的Map或者Reduce操作,单个reduce操作的输出对应于整个程序某次序列化输出的结果。
Locality
由于在计算环境中,网络带宽是很重要的资源,所以谷歌文件系统将输入数据平分,存储到本地磁盘上,而且一般会进行3备份。在运行过程中,MapReduce操作会从本地读取。
Task Granularity
M和R的任务数量应该要比worker机器要多,这样使得worker可以执行多种任务,从而提高负载均衡,也可以在某个worker挂掉的时候快速恢复,因为它已经完成的大量map任务都可以重新分配给其它worker机器上执行。
因为master进行任务分配决策的复杂度是O(M+R),并且需要在内存中使用O(M*R)大小的空间来保存之前所说的状态。
Backup Tasks
因为某些机器磁盘的故障等原因,MapReduce任务会变得特别慢。这时MapReduce采用的机制就是:
- 在整个计算快要结束时,将一些还在进行的任务进行backup,当backup任务或者源任务其中一个完成时,我们就任务整个计算完成了
Refinements
Partitioning Function
该函数的作用是将中间key结构划分为R部分,默认使用hash(key) mod R,但也可以根据需求自定义
Ordering Guarantees
这个函数主要是对中间结果根据key进行排序
Combiner Funct
该函数是在执行map任务的机器上操作的,将一些数据合并起来,然后写到中间结果去。
Input and Output Types
Mapreduce支持三种文件格式:第一种是逐行读入,key是文件偏移,value是行内容;第二种是key/value读入;第三种是用户自定义reader,可以从文件、数据库或者内存中的数据结构读取。
Side-effects
MapReduce允许用户生成额外的输出,但其原子性应该由应用本身来实现
Skipping Bad Records
对于一些不好修复的bug,或者确定性的错误。worker通过一个信号处理器来捕获错误,然后在执行Map或者Reduce操作前,MapReduce会存储一个全局序列号,一旦发现了用户代码的错误,信号处理器就会发一个内含序列号的UDP包给master,如果master发现了特定记录有了多次的失败,就会指示该记录应该跳过,不再重试。
Local Execution
因为分布式环境调试不方便,MapReduce提供在本机串行化执行MapReduce的接口,方便用户调试。
Status Information
master把内部的状态通过网页的方式展示出来
Counters
MapReduce提供一个计数器来计算各种时间的发生频率。例如这样:
1 | Counter* uppercase; |
计数器的值会周期性传达给master。当MapReduce操作完成时,count值会返回给用户程序,需要注意的是,重复执行的任务的count只会统计一次。