Generative Models
概述
Given training data, generate new samples from same distribution.
这是非监督学习的一种,目标是学习生成一个模型。使用Generative Models,我们可以构造一些艺术工作的真实样式,通过时间序列的数据去仿真,还有就是Generative Models可以用来推荐潜在的表示模式。
Generative Models有两种:Explicit density模型和implicit density模型。
生成模型族谱:

Pixel Rnn & Pixel Cnn
在讨论具体的显式密度模型之前,我们先来看一下完全可见置信网络 Fully visible belief networks。该模型通过使用概率的链式规则来将一个n维的向量x的概率分布分解为一个一维的概率分布: \[ P_{model}(x) = \prod_{i=1}^{n}P_{model}(x_i|x_1,...,x_{i-1}) \]
- Pixel Rnn
从Corner开始生成图像像素,然后往周边序列化地生成像素,一般可以通过RNN或者LSTN去生成周边的像素。缺点就是序列化生成非常慢。
- Pixel Cnn
跟前面一样,从Corner开始生成图像像素。但不同的是,下一个像素的生成是利用上一个像素丢入CNN后生成的。相对pixel rnn会更快,但是总体来说还是比较慢的。
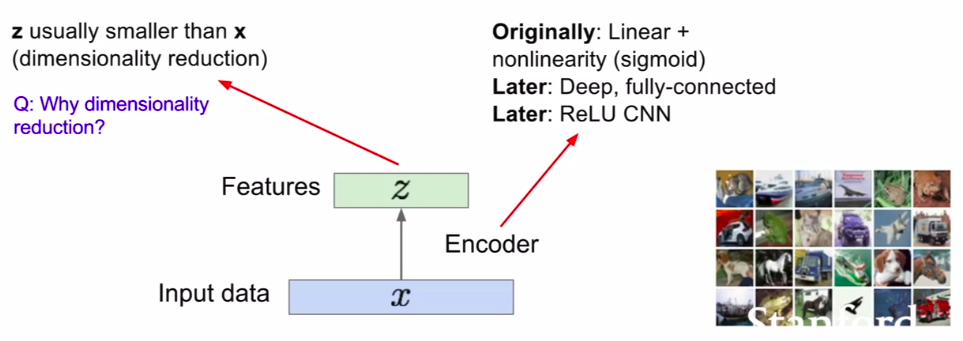
Autoencoders
这是非监督学习的一种方法,可以从没有标记过的数据中学习到一些低维度的特征。z是比x维度更低的数据,z包含了重要的信息,并且z应该能够学习到可以被抓取的特征。z能够通过decoder重建输入数据。
GAN
GAN的提出是为了解决从一个复杂的、高维的训练分布数据中进行采样的问题,我们可以从一个简单分布进行采样,例如随机噪声,然后去学习transformation到训练的分布。我们使用神经网络去表示这个复杂的transformation。
Two player game
- Generator network: try to fool the discriminator by generating real-looking images;
- Discriminator network: try to distinguish between real and fake images;
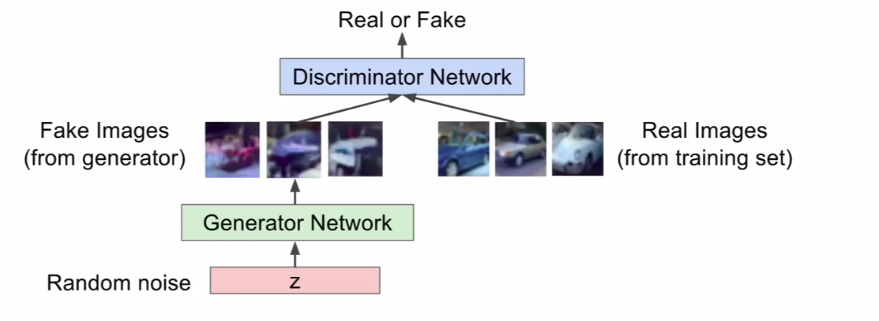
目标函数: \[ \underset{\theta_g}{min}\ \underset{\theta_d}{max} [E_{x-p_{data} }logD_{\theta_d(x)} + E_{x-p_z }log(1-D_{\theta_d}(G_{\theta_g}(z)))] \] 其中,\(D_{\theta_d(x)}\)是真实数据x的Discriminator的输出,\(D_{\theta_d}(G_{\theta_g}(z))\)是假数据的输出。Discriminator想要最大化目标函数,使得D(x)接近1,并且D(G(z))接近0;而Generator则是最小化目标函数,使得D(G(z))接近1。