聚类
聚类任务
在无监督学习中,由于训练样本是未标记的,因此如果希望对无标记的训练样本进行深入挖掘,可以采用聚类(clustering)的方法。
假设有样本集D = {x1,x2...xm},则聚类算法就是将样本集D划分为k个不相交的簇{Cl|l=1,2,...,k}。
作为一种无监督学习的算法,它既可以用于寻找数据内在的分布结构,也可以作为其它学习任务的前驱过程。
性能度量
性能的度量主要是为了评估聚类结果的好坏,一般来说我们使用两种方法:
- 将聚类结果与某个“参考模板”进行比较,也就是使用外部指标。
假设λ与λ分别表示C和C对应的簇标记向量,我们将样本两两配对考虑。
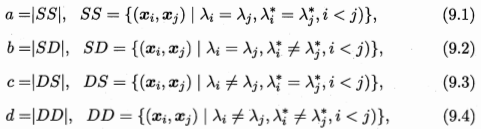
其中集合SS包含了在C中属于相同簇,且在C也属于相同簇的样本对; 集合SD则是包含了在C中属于相同簇,但在C中不属于相同簇的样本对; 如此类推。。。。
由于每个样本对(xi,xj)只能出现在一个集合中,因此有a+b+c+d=C(m,2)=m(m-1)/2。
最后导出以下的外部度量指标:
- Jaccard系数: JC = a/(a+b+c)
- FM指数:FMI = √(a/a+b)*(a/a+c)
- Rand指数:RI = 2(a+b)/(m*(m-1))
上述指标都在[0, 1]之间,值越大越好
- 直接考虑聚类结果,不参考任何的模型




其中dist(.,.)用来计算两个样本之间的距离;diam(C)表示簇C内样本间的最远距离;dmin(Ci,Cj)对应于簇Ci与Cj最近样本的距离;dcen(Ci,Cj)表示簇Ci与簇Cj中心点间的距离
一般用以下的指标去评估聚类性能:
- DB指数:

- Dunn指数:

显然,DBI越小越好,表示簇内距离小,簇间距离大;而DI则相反,越大越好,表示簇间距离大,簇内距离小
距离计算
一般来说,我们希望函数dist(.,.),也就是距离度量,满足以下的一些基本性质:
- 非负性:dist(xi,xj)>=0
- 同一性:dist(xi,xj)=0,当且仅当xi=xj
- 对称性:dist(xi,xj)=dist(xj,xi)
- 直递性:dist(xi,xj)<=dist(xj,xk)+dist(xk,xj)
在讨论距离计算时,属性是否有序很关键,例如定义域为{1,2,3}的属性,能直接在属性值上计算距离,这种就称为有序属性;而对于定义域为{飞机,火车,轮船}这些,称为无序属性
有序属性
给定样本xi=(xi1,xi2,...,xin)与xj=(xj1,xj2,...,xjn),最常用的就是Minkowski distance

当p=2,也叫欧式距离
无序属性
首先来看几个假设:m(u,a)表示在属性u取值为a的样本数,m(u,a,i)则是表示第i个样本簇在属性u取值为a的样本数。于是得到以下的公式(VDN)来计算距离。

另外,还可以结合Minkowski distance和VDM,保证处理混合属性

但对于无序属性,有可能会出现直递性失效,以“人”,“马”,“人马”为例,“人”和“马”都与“人马”很接近,但“人”与“马”差距很大,这种就叫做非度量距离。
原型聚类
prototype-based clustering,此类算法假设聚类结构能够基于一组原型刻画
k-means 算法
对于一个样本集和目标簇数,我们希望最小化以下的误差,其中ui就是簇Ci的均值向量。

算法思想比较简单:
1 | 1. 随机选择k个样本作为初始的均值向量 |
学习向量量化
Learning Vector Quantization是针对带有标记的数据样本的。对于这种情况,我们可以根据簇数选择一组n维向量(维度与样本一致)
具体算法为:
1 | 1. 首先初始化一组原型向量 |
这里的关键是如何更新原型向量:
- 如果类型一致:新的向量 p = pi + u(xj-pi);
- 如果类型不一致: p = pi - u(xj-pi);
这里的u是学习率,范围为[0,1]。之所以满足逼近或者离得更远:
|p-xj| = |pi+u(xj-pi)-xj| = (1-u)|pi-xj|
由此可见,这种情况下p会在更新之后逼近xj
高斯混合聚类
高斯混合聚类采用的是概率模型来表达聚类原型,我们定义高斯混合分布公式为:

该分布为k个高斯分布的叠加,其中ai为相应的混合系数,且权重和为1。
算法步骤为:
1 | 1. 初始化混合高斯分布的三个模型参数:ai,ui(平均值),协方差矩阵 |
至于如何求解这三个参数,可以参考EM算法:https://blog.csdn.net/u011974639/article/details/78302024
简单概括,就是两步:
- 先根据上一轮的参数来计算每个样本属于每个高斯分布的后验概率;
- 再根据后验概率去更新参数;
密度聚类
这个算法假设聚类结构能够通过样本分布的紧密程度来确定,先来确定几个概念:
- 邻域:对于样本集中的xj,邻域包含了样本集中与xj距离不大于某个值的样本
- 核心对象:若xj的邻域包含了至少MinPts个样本,则xj就是一个核心对象
- 密度直达:若xj位于xi的领域中,则xj由xj密度直达
- 密度可达:若存在样本序列p1,...,pn,其中p1=xi,pn=xj,且pi+1可由pi密度直达,则称xj可由xi密度可达
具体算法:
1 | 1. 首先根据邻域参数选出所有的核心对象; |
层次聚类
层次聚类可以采用“自底向上”或者“自顶向下”的策略,在这里我们介绍AGNES的策略,这是一种自底向上的聚合策略。
它首先将每个样本看成一个初始聚类簇,然后在每次算法运行时找出距离最近的两个聚类簇进行合并,因此这里的关键就是计算两个聚类簇之间的距离,显然最小距离由两个簇的最近样本决定,最大距离由两个簇的最远样本决定,至于平均距离则是由两个簇的所有样本共同决定。