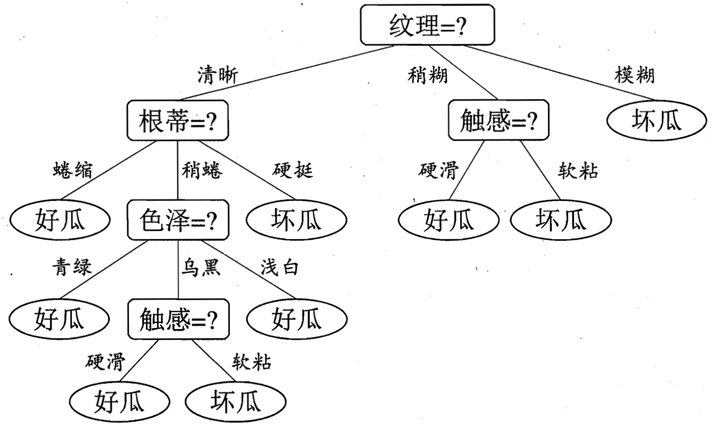
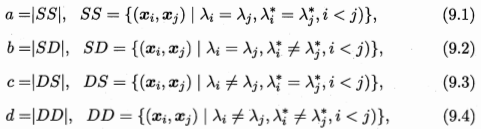抽象语法
Abstract: disassociated from any specific instance
语义动作
每个终结符和非终结符都可关联一个语义值类型。
递归下降
在递归下降的语法分析器中,semantic action是语法分析函数所返回的值,或者是这些函数所产生的副作用。
抽象语法分析树
为了有利于模块化,我们尽量将语法分析和语义分析分开处理,往往的一个做法就是由语法分析器生成一种数据结构——语法分析树,编译器在后面的阶段对其进行后序遍历。但如果遇到了引入新的非终结符和文法production的情况,我们应该尽量将这些细节限制在语法分析,而不应该干扰语义分析。
抽象语法就是起到了在语法分析与编译器等后面阶段之间建立接口的作用。
位置
有只过一遍的编译器中,词法分析,语法分析和语义分析是一起进行的。因此发送错误时,我们可以取得词法分析的当前位置,因为这里是最接近错误源的位置。而如果使用了抽象语法分析树之后,进行遍历时如果出现了语义错误,就不能简单地判断此时词法分析的位置,因为此时词法分析已经到了文件末尾。
因此,我们需要记录每一个节点在源程序中的位置。