I/O复用:select和poll函数
概述
IO复用:一旦一个或者多个IO条件就绪了,内核就会通知进程
应用场景:
- 当客户处理多个描述符,例如交互输入和网络套接字
- 一个客户处理多个套接字
- 服务器既要处理监听套接字,又要处理已连接套接字
- 服务器既要处理TCP,又要处理UDP
- 服务器处理多个服务或者多个协议
I/O模型
阻塞型I/O;非阻塞型I/O;I/O复用;信号驱动式I/O;异步I/O
套接字上的输入分为两步:首先是等待数据从网络中到达。到达后会先将数据复制到内核缓冲区,接着复制到应用进程缓冲区。
阻塞式I/O模型
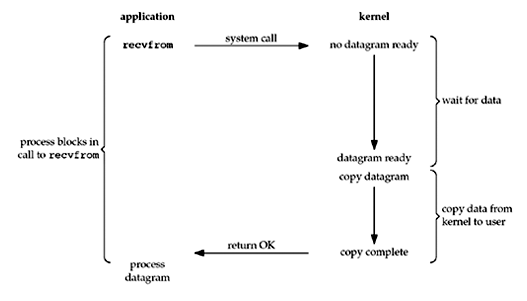
进程在调用recvfrom()之后,一直阻塞直到数据复制到应用进程缓冲区或者返回错误
非阻塞式I/O模型
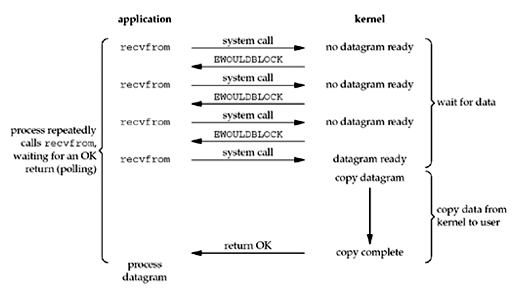
应用进程持续的轮询,查看操作是否就绪。如果没有就绪就会返回一个错误。这种做法会耗费大量的CPU时间
I/O复用模型
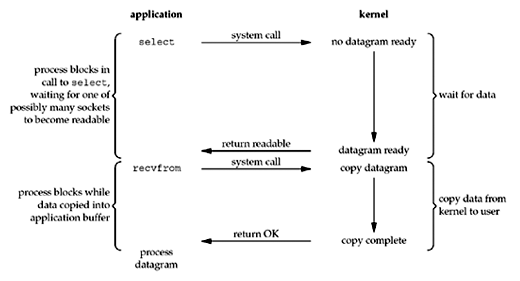
对于这种模型,我们可以使用select或者poll来完成我们的需求。通过select这个系统调用(阻塞于此),让内核在IO就绪的情况下通知应用进程,然后应用进程再调用recvfrom。这里使用了两个系统调用,但好处是可以等待多个描述符就绪。
信号驱动式I/O
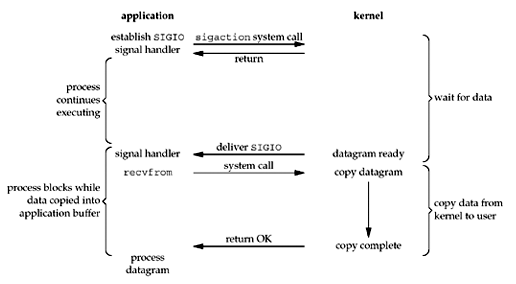
对于这种模型,首先是安装一个信号驱动函数,并马上返回。在内核发现描述符就绪后,通过信号通知应用进程。这样,在等待数据到达的期间进程不会被阻塞。
异步I/O
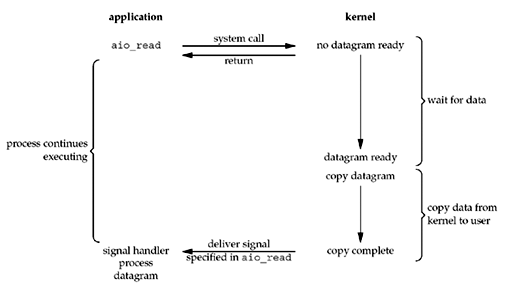
这种模型比之信号驱动式I/O更绝,它是内核完成IO操作之后才会通知应用进程
前面四种模型都是同步I/O模型,因为进程都会因为IO请求而阻塞,知道IO操作完成
select函数
先来看函数原型:
1 |
|
对于最后一个函数,这是一个时间参数,控制的是在内核等待操作就绪需要花费多少时间:
- 永远等待,直到有一个描述符就绪。设置为NULL
- 等待一定的时间,在时间范围内直到有一个描述符就绪
- 不等待,轮询,马上返回
至于中间三个参数:readset,writeset,exceptest。控制的是内核需要测试哪些描述符的读写,异常操作。
注意的是,fd_set是一个描述符集,通常是一个整数数组。每个元素是32位,每一个位对应的是一个描述符,其中第一个元素对应的是描述符0-31,第二个元素对应的是32-63。例如,3对应的就是描述符123。通过某些宏定义的操作可以设置需要检查的描述符。
另外就是,由于这里传入的指针会被修改,也就是作为值——结果返回。通过调用select之后检查指针的值就知道哪些bit修改了,也就是描述符的操作就绪了。也因此,每次调用select都要重新设置。
第一个参数就是待测试的最大描述符+1,也就是测试的描述符个数。
描述符就绪条件
| Condition | Readable? | Writable? | Exception |
|---|---|---|---|
| Data to read | x | ||
| Read half of the connection closed | x | ||
| New connection ready for listening socket | x | ||
| Space available for writing | x | ||
| Write half of the connection closed | x | ||
| Pending error | x | x | |
| TCP out-of-band data | x |
shutdown函数
1 |
|
- 与close函数相比,shutdown函数不需理会引用计数是否为0,它可以直接激发TCP的正常连接终止;
- 另外,close终止的是读与写两个方向的数据传送,而shutdown函数则是告诉对端我们已经完成了数据传送,即使对端仍有数据发送。
也就是shutdown函数的调用会关闭一半的TCP连接。
poll函数
1 |
|
poll函数与select类似,但它能提供额外的信息,而且用的不是值——结果参数。
注意第一个参数,fdarray是这样的一个结果体指针:
1 | struct pollfd { |
需要测试的条件由events指定,函数会在revents成员中返回描述符的测试结果。具体表现如下图:
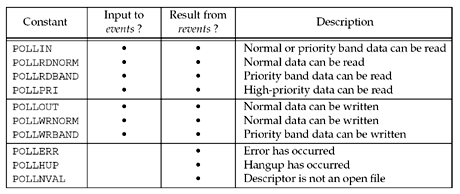
从这个表可以看到,我们可以测试读写和异常三种操作,另外还能识别三类数据:普通数据,优先级带,高优先级带。至于怎么区分这些数据的类型,就有些争议了,这里就不写了。
timeout参数跟select的类似,也是指定poll函数返回前等待多长时间。
- INFTIM:永远等待
- 0:立即返回,不阻塞进程
0:等待指定的时间